ETL
مقدمه
در دنیای واقعی، دادهها از منابع مختلف و با ساختارهای متفاوت جمعآوری میشوند. در این فاز میخواهیم دادهها را مورد پردازش قرار دهیم و به یک خروجی مناسب برسیم؛ برای این کار باید تمام دادهها را جمعآوری کنیم، آنها را تمیز کنیم، تبدیلات مورد نیاز را انجام دهیم و آنها را به یک ساختار و استاندارد یکسان در آوریم.
به فرآیند انتقال داده از یک یا چندین منبع به یک سیستم مقصد که داده را بهصورت متفاوتی بازنمایی میکند ETL گفته میشود که مخفف عبارت Extract, Transform & Load است.
تعریف
Data Extraction (استخراج داده)
در این مرحله دادۀ خام از منابع مختلف به یک فضای میانی منتقل میشود. منابع مبدأ میتوانند دارای دادۀ ساختاریافته یا غیرساختاریافته باشند. از انواع منابع داده میتوان به موارد زیر اشاره کرد:
- SQL or NoSql Servers
- Flat Files
- Emails
- Web Pages
Data Transformation (تبدیل داده)
دادۀ خام در فضای میانی مورد پردازش قرار میگیرد تا به ساختاری که برای تحلیل داده مورد نیاز است تبدیل شود. این مرحله میتواند شامل موارد زیر باشد:
- فیلتر کردن
- تمیزسازی
- حذف دادههای تکراری
- اعتبارسنجی
- انجام محاسبات، ترجمه و یا خلاصهسازی که میتواند شامل موارد زیر باشد:
- تغییر نام ستونها
- تبدیل واحدهای پول
- تبدیل واحدهای اندازهگیری
- ویرایش ستونهای متنی
- حذف یا رمزنگاری دادههای حساس یا محرمانه
- تبدیل ساختار داده به ساختار مقصد؛ بهعنوان مثال تبدیل JSON به یک یا چند جدول که میتوان آنها را Join کرد.
Data Loading (بارگذاری داده)
در این مرحله دادۀ تبدیلشده در مرحلۀ قبل، از فضای میانی به انبار دادۀ مقصد منتقل میشود. این مرحله معمولاً غیر از بارگذاری اولیه، بهصورت متناوب نیز اجرا میشود تا دادههای جدید به انبار داده اضافه شوند. در اکثر موارد این فرآیند بهصورت خودکار انجام میشود.
برای آشنایی بیشتر با این مفهوم میتوانید از لینکهای زیر استفاده کنید:
یادگیری
ثبتنام
در وبسایت Talend ثبتنام کنید. از شما اطلاعاتی مانند ایمیل کاری، شماره تلفن، نام شرکت، عنوان شغلی و ... خواسته میشود که میتوانید از ایمیل شخصی خود استفاده کنید و سایر فیلدها را با اطلاعات نادرست پر کنید.
پس از ثبتنام، لینکی به ایمیل شما فرستاده میشود که از طریق آن میتوانید وارد اکانت خود شوید و تا 14 روز از سایت استفاده کنید.
پس از ورود به اکانت، بر روی دکمۀ Discover کلیک کنید تا لیست تمام ابزارها را ببینید.
برای استفادۀ کامل از امکانات سایت احتیاج به قندشکن خواهید داشت.
ورود داده
در بخش Data Inventory با استفاده از گزینۀ Drop a file or browse، دیتاست زیر را آپلود نمایید. این دیتاست شامل آمار مبتلایان و تلفات کرونا به تفکیک کشورهاست که روزانه بهروزرسانی میشود. از آنجایی که حجم این دیتاست بسیار زیاد است، میتوانید از دیتاست کمحجم نیز استفاده کنید.
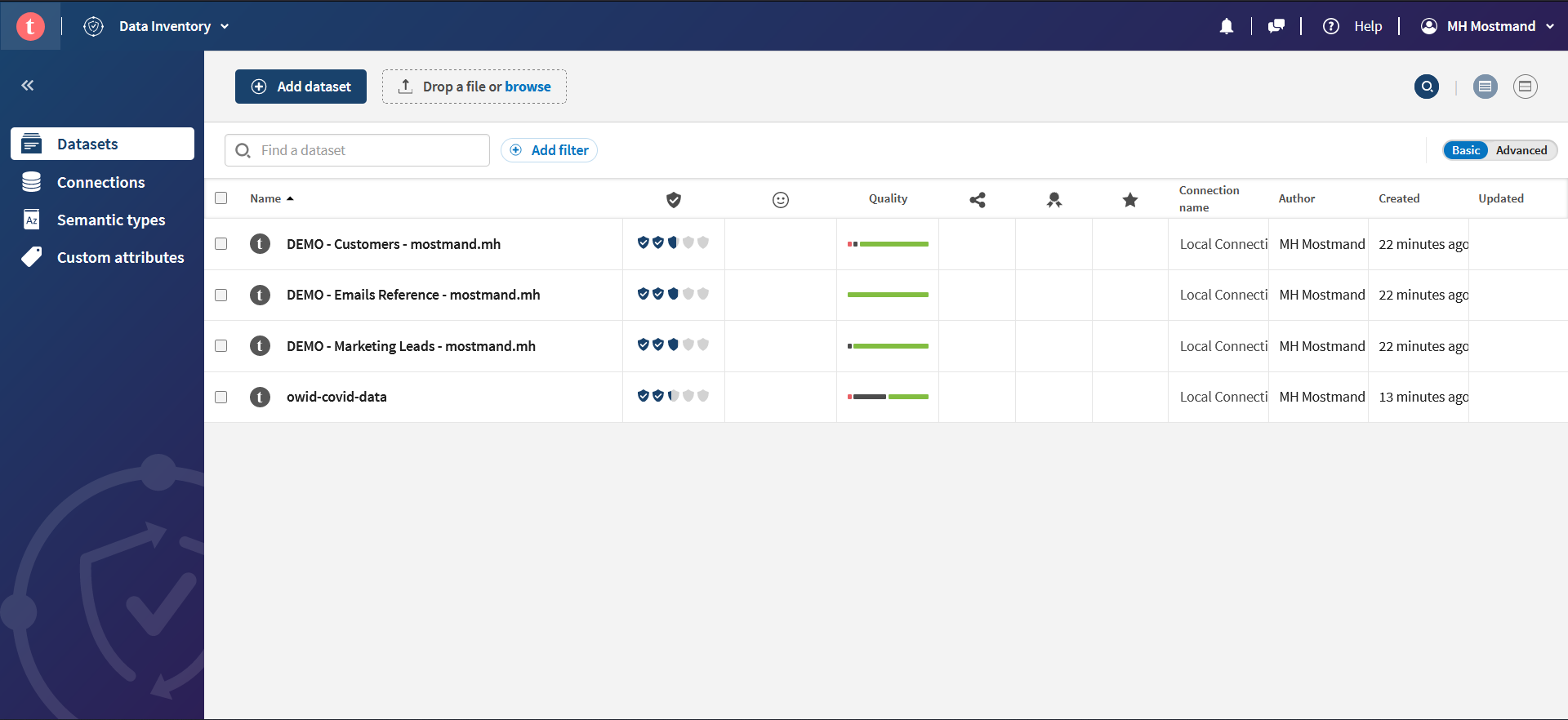
پس از آنکه فرآیند آپلود تمام شد، میتوانید دیتاست را در لیست مشاهده کنید و با کلیک بر روی آن اطلاعات تکمیلی را ببیند:
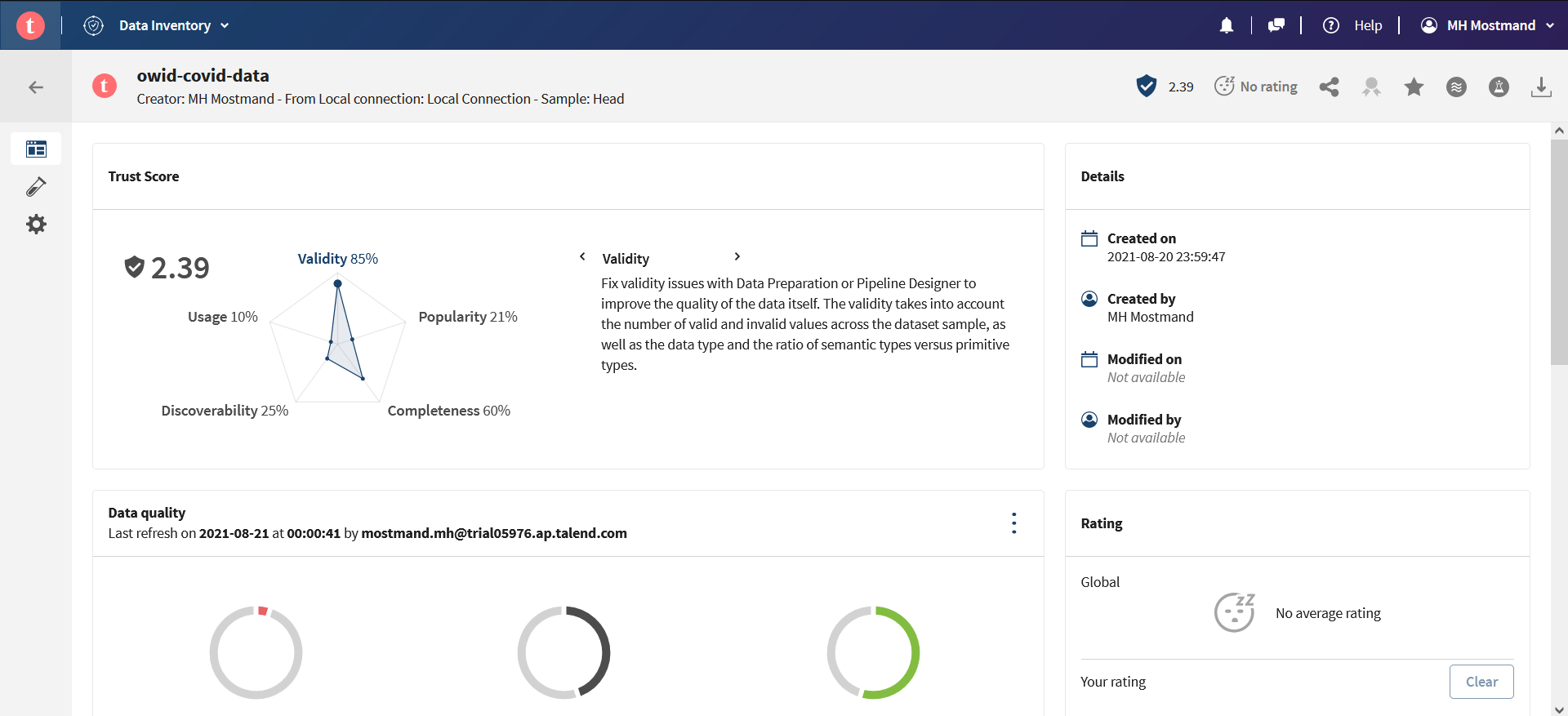
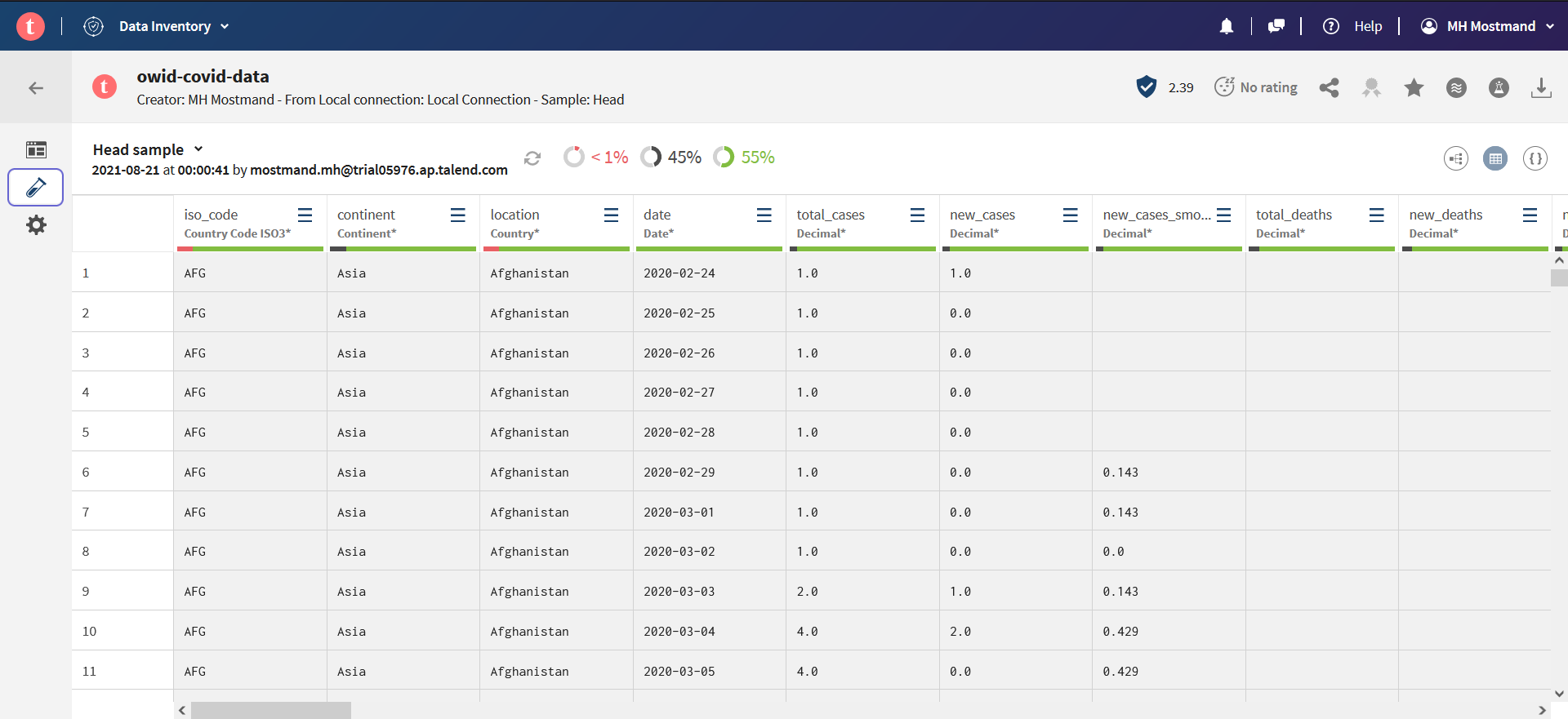
روی آیکن لولۀ آزمایش که در سمت چپ قرار دارد کلیک کنید تا بتوانید نمونهای از دادۀ آپلود شده را مشاهده کنید:
ساخت Pipeline
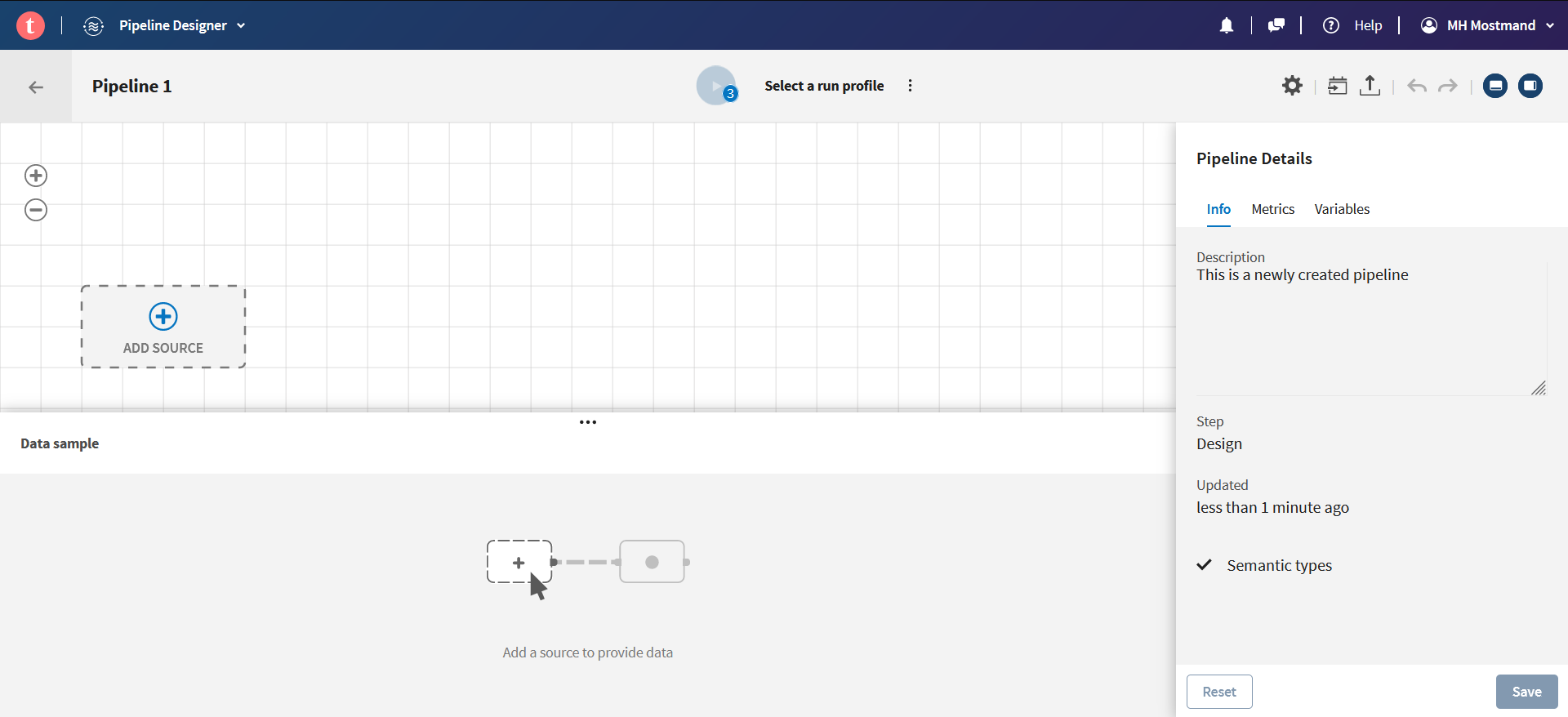
وارد بخش Pipeline Designer شوید و بر روی دکمۀ Add pipeline کلیک کنید تا یک Pipeline جدید ساخته شود.
تعیین مبدأ
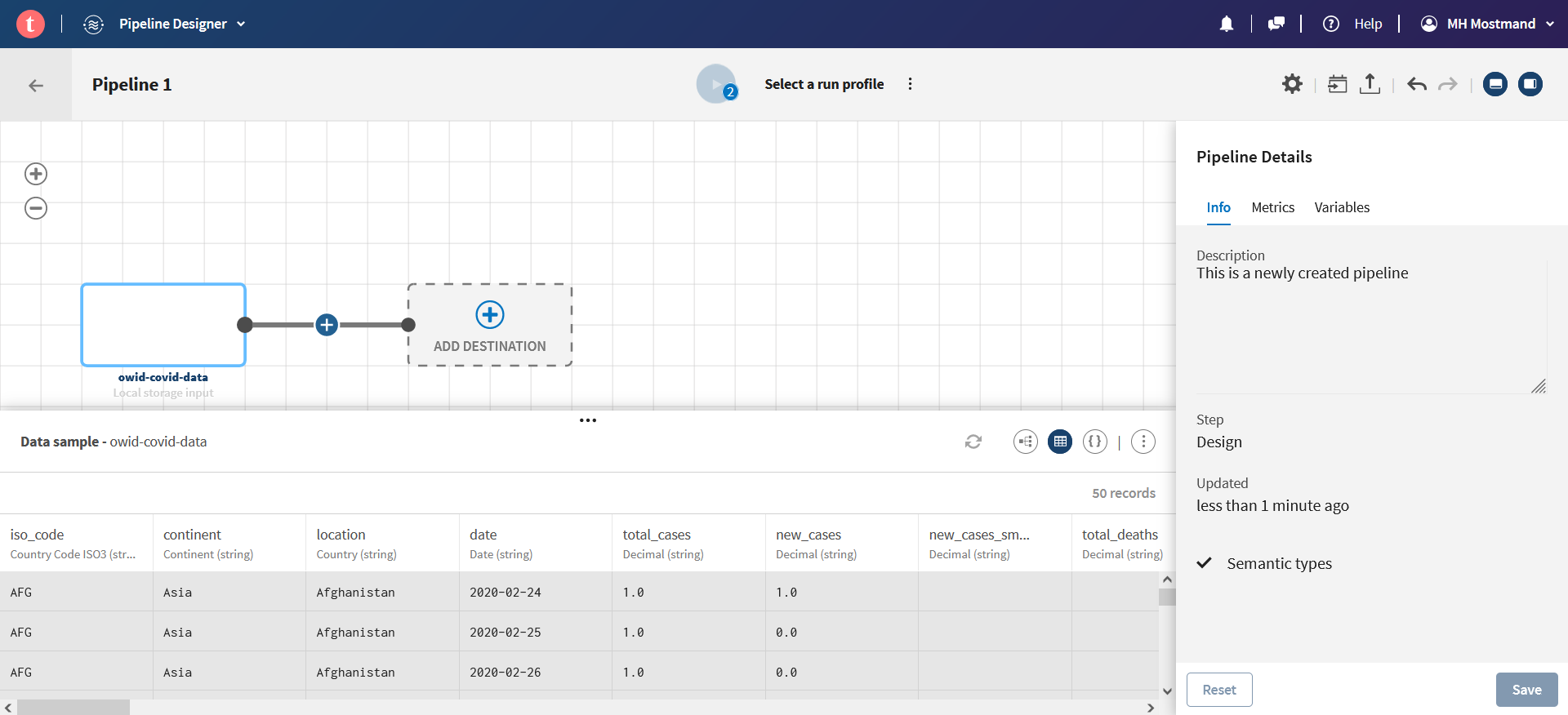
روی ADD SOURCE کلیک کنید و دیتاست آپلودشده را انتخاب نمایید:
تعیین مقصد
روی ADD DESTINATION و سپس Add dataset کلیک کنید سپس یک نام دلخواه برای آن در نظر بگیرید. قسمت Connection را بر روی Local Connection بگذارید؛ در این صورت پس از اجرای Pipeline، داده با نام تعیین شدۀ شما در Data Inventory قابل مشاهده خواهد بود.
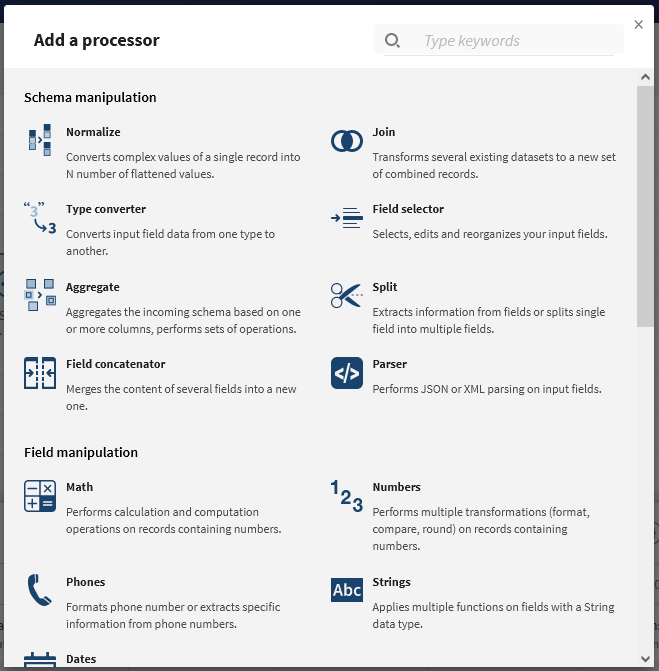
پردازشگر
با کلیک بر روی دکمۀ + میتوانید Processor اضافه کنید. هرکدام از Processorها یک عملیات را بر روی داده انجام میدهند.
فیلتر دادهها
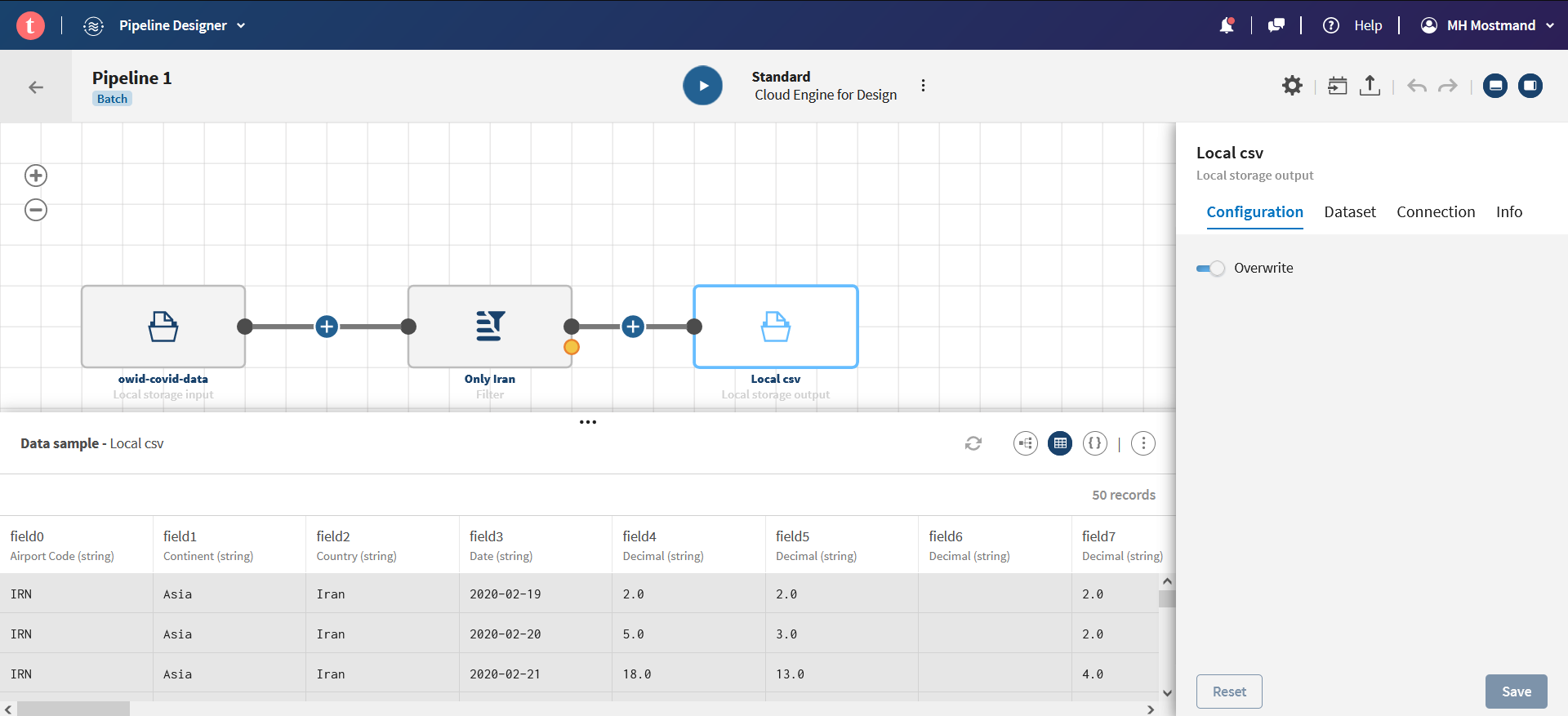
با استفاده از Filter Processor دادههای مربوط به کشور ایران را فیلتر نمایید.
دقت کنید که پنل Preview صرفاً 100 رکورد اول را نمایش میدهد. بنابراین ممکن است پس از فیلتر به نظر برسد هیچ دادهای وجود ندارد.
اجرا
از بالای صفحه بر روی Select a run profile کلیک کنید و در منوی باز شده گزینۀ Standard را انتخاب نمایید. پس از این کار دکمۀ اجرا در دسترس شما خواهد بود:
Pipeline را اجرا کنید و پس از اتمام، نتیجۀ آن را در Data Inventory مشاهده نمایید.
تمیزسازی
مراحل زیر را برای تمیزسازی داده انجام دهید:
قسمت اعشاری ستونهای
new_casesوnew_deathsرا حذف نمایید.مقادیر خالی (NaN یا null) را در ستون
.new_vaccinations_smoothedبا مقدار صفر جایگزین نمایید.نوع ستون
dateرا ازStringبهDateتبدیل کنید.
Aggregation
جمع تعداد موارد ابتلا در هر ماه را محاسبه کنید و در ستونی به نام total_month_cases بریزید.
برای این کار ممکن است لازم باشد ابتدا روی ستون تاریخ تغییراتی انجام دهید.
Join
دیتاست موقعیت جغرافیایی کشورها را آپلود نمایید سپس با استفاده از Join، ستونهای طول و عرض جغرافیایی را به دیتاست آمار مبتلایان اضافه نمایید.
دریافت خروجی
در نهایت، حاصل کار خود را در قالب یک فایل CSV خروجی بگیرید و دانلود نمایید و نتایج را مشاهده کنید.
شما میتوانید در پروژۀ خود علاوه بر خروجی متنی، خروجی نموداری را نیز با استفاده از کتابخانههایی مانند Highcharts اضافه کنید. این کتابخانه بهصورت رسمی از Angular پشتیبانی میکند. اطلاعات تکمیلی را میتوانید در صفحۀ GitHub آن مشاهده کنید.
اشتراکگذاری
توصیه میکنیم Pipeline خود را با اعضای تیم به اشتراک بگذارید، Pipeline آنها را نیز بررسی کنید و روشهای مورد استفاده را ببینید. برای این کار میتوانید از آیکن Export the pipeline استفاده کنید.